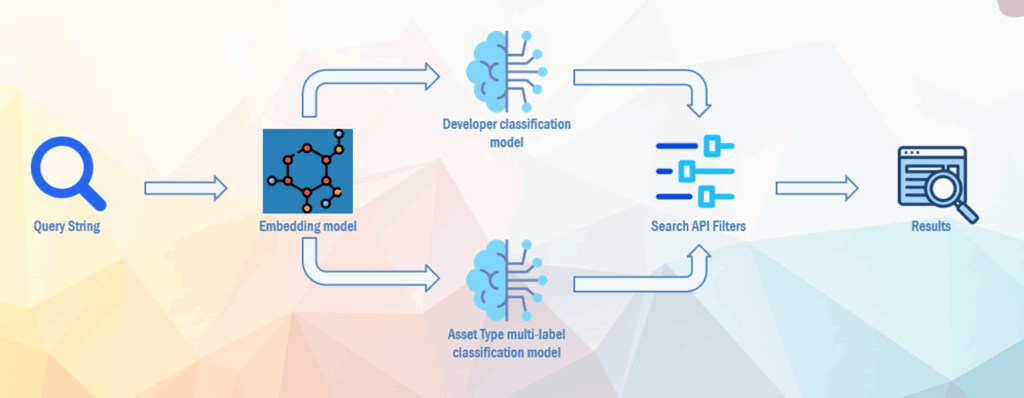
As part of the ongoing development of the FAME marketplace, a key objective is to provide an intelligent search experience that helps future users discover relevant resources through simple, free-text queries.
To improve the search experience, FAME Search Engine uses filters that can be semantic interpreted such as:
- The developer or organization responsible for the asset.
- The type of the asset (e.g., model, dataset, documentation).
We have designed a hybrid classification system that interprets natural language queries and predicts these attributes, even when the phrasing is informal, abbreviated, or contains typos.
Preprocessing: Preparing the Query for Analysis
Before any semantic processing takes place, each user query undergoes a preprocessing step designed to improve input quality. This includes operations such as lowercasing, punctuation removal, and basic typo correction using rule-based and dictionary-based methods.
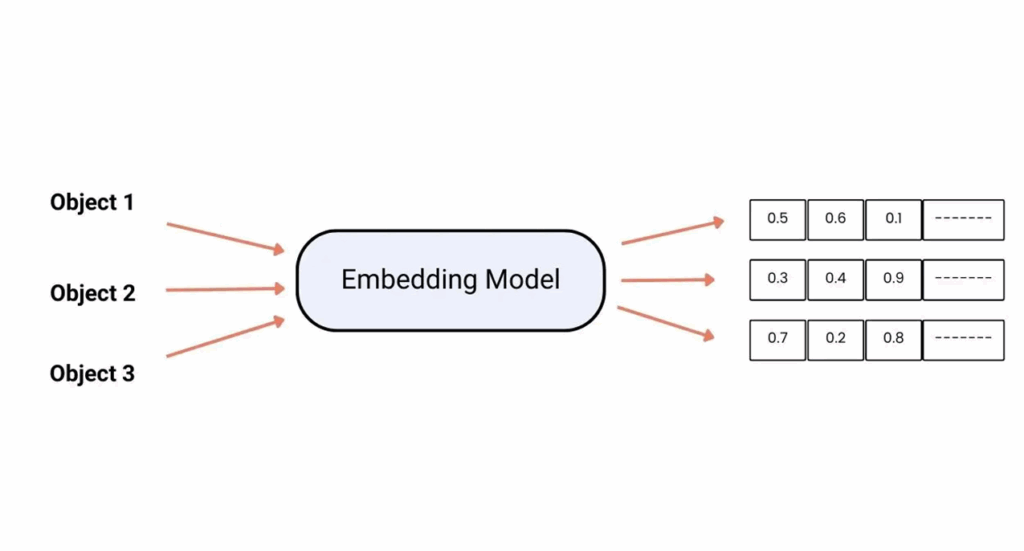
Semantic Embeddings: Capturing Meaning
Each query is first transformed into a semantic embedding using a pretrained language model. This process generates a numerical representation that reflects the meaning of the query, not just the words it contains. For example, the phrases “JOT performance predictor” and “predictive model by JOT-Internet Media” are mapped to similar vectors, enabling the system to recognize their shared intent.
A Hybrid Strategy: Matching and Classification
Once the query is embedded, the system compares it to known developer names and asset types using vector similarity. If a confident match is found, the metadata is inferred directly.
If the similarity score is below a defined threshold, the system relies on a supervised classification model. This fallback mechanism ensures robustness, especially for queries that are ambiguous.
By combining semantic matching with machine-learned classification, the hybrid model balances precision and adaptability.
Looking Ahead
The system will have the opportunity to evolve based on real user behaviour. By logging anonymized queries and model predictions, we plan to establish a feedback loop that enables periodic retraining of both the embedding-based similarity component and the classification models.
Retraining with production data ensures the service remains accurate, relevant, and responsive to the needs of its users.
Author: Raúl Encinas (Data Scientist in JOT Internet Media)
—
Subscribe to our newsletter for the latest updates, and follow FAME on LinkedIn and X to be part of the journey.
More info:
JOT