In the last few months, FAME partners have had their hands full with the development and implementation of two brand new demos showcasing some of the most horizontal functionalities FAME will offer. In this post, we summarize the second demo, which is related with showing some of the analytics WP5 is going to offer to FAME users.
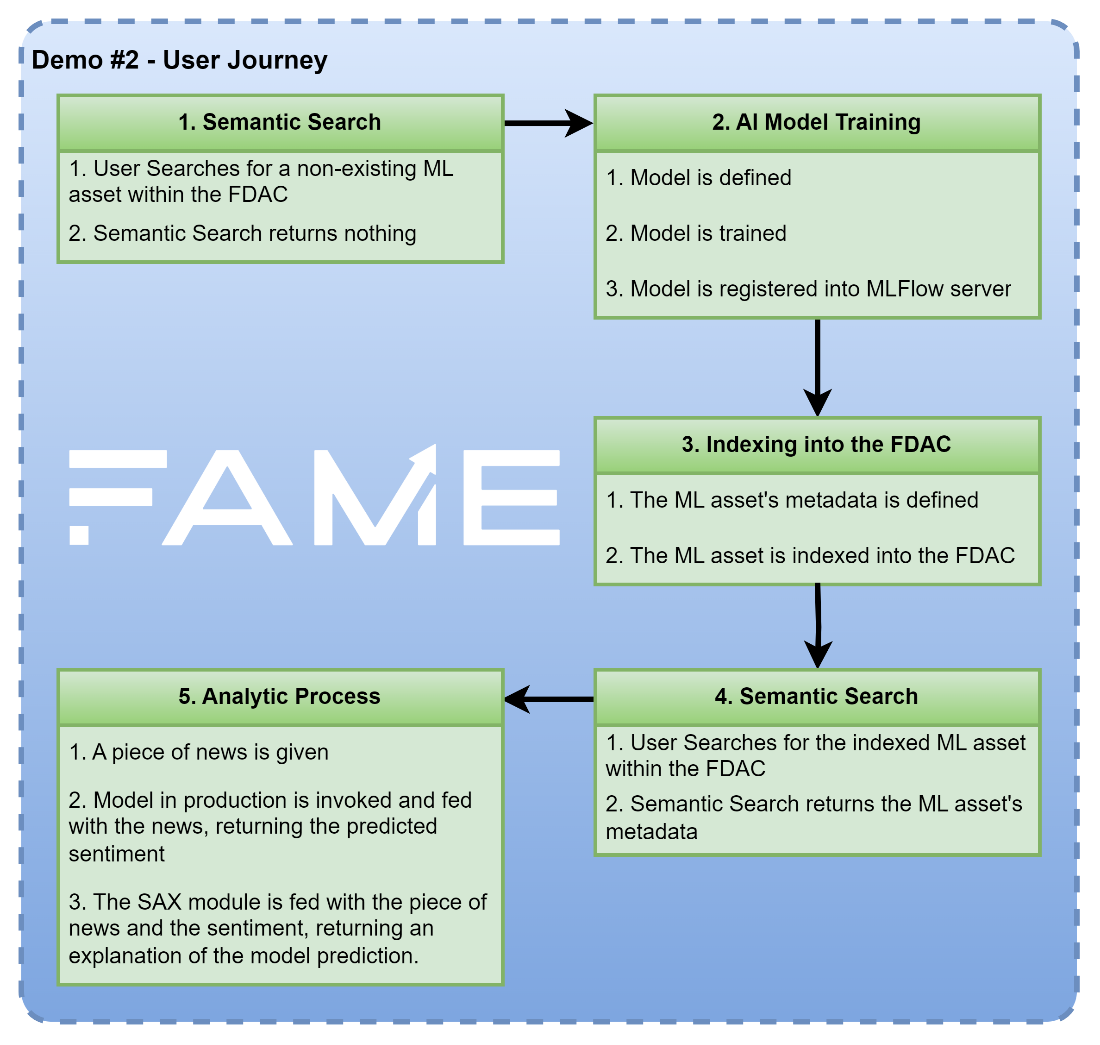
FAME Demo #2, presented at the last General Assembly of the project in Oslo on 29 November, was designed to demonstrate some functionalities related to Semantic Search, Federated Data Asset Catalogue (FDAC) and the analysis tools, comprising the Machine Learning (ML) tools and the Situation Awareness Explanation (SAX) tools. This demo has been the result of the joint effort of JOT, UNP, ATOS and IBM during these last months.
More specifically, these components have been demonstrated by using part of the 2nd use case of Pilot 5. This scenario proposes to create ML models that would be able to understand financial news and infer whether the specific piece of news would have a positive impact on a company or not. In addition, ML assets should be indexed in the FDAC and users should be able to find them using semantic queries.
JOT presented an initial approach to how FAME users could search for assets within the FDAC using semantic queries and the user interface that will be used. This component will allow users to better filter these assets by simply writing a description of what they need.
UNP has provided an API to better index assets in the FDAC by setting some metadata describing the asset itself, including, for instance, the name of the asset, a URL where the asset can be accessed, and the name and affiliation of the developers.
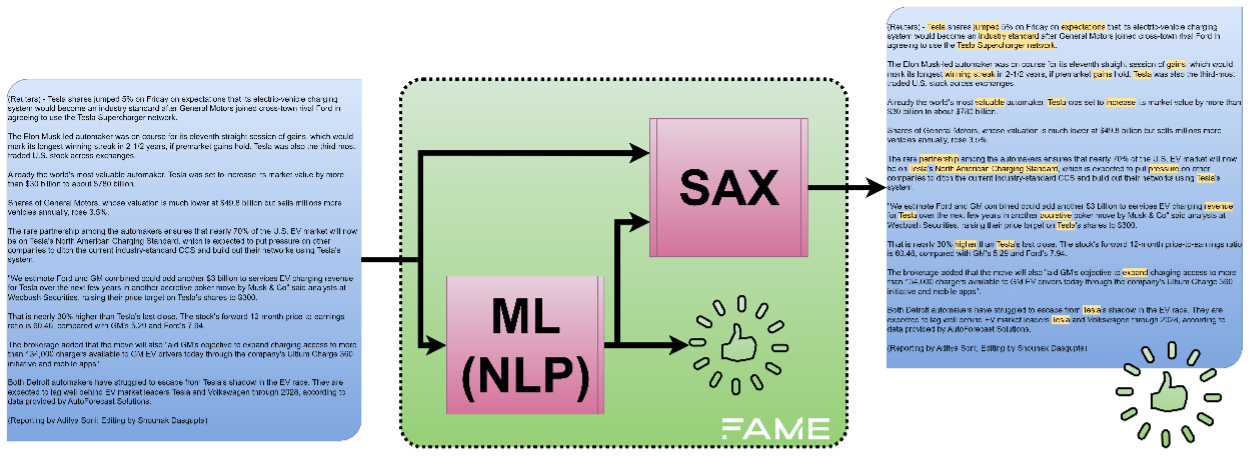
ATOS proposed an infrastructure that will allow AI developers to build and train models and store them in an MLFlow repository, which will also be indexed in the FDAC. This would allow them to create the ML asset catalogue. In addition, this infrastructure allows users to perform inference on the given financial news with the available NLP models using an endpoint input.
IBM has implemented a SAX tool that can explain the inferences provided by the NLP models of the FAME AI/ML catalogue. This system relies on Large Language Models (LLMs) to explain the estimated sentiment associated with the given news in such a way that the most relevant words are highlighted. These words are later used in an iterative process to confirm if they are the most relevant by inferring the sentiment of this set of words using the NLP model and checking whether they provide the same sentiment as the whole news or not.