LeanXcale is developing within the FAME project a novel innovation, named Energy Efficient and Incremental Analytics, whose purpose is twofold: firstly to provide the capability of incremental processing of analytical operations and secondly, to perform analytical query processing with an energy efficient manner.
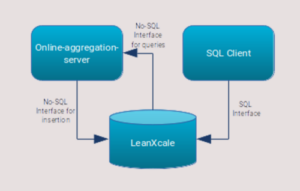
Regarding the incremental analytics part of this artefact, it is important to highlight that with this term we refer to the analytical query operations that can be found in a relational database. These can be used by AI analytical processing in order to push such operations down as closest to the storage. The benefit for the end-user, the data analyst or application developer, is that they do not have to bother on how to execute such complex operations, but instead, leave the database to perform those on their behalf. By doing so, the data analyst or application developers do not need to read enormous volumes of data, transmit them to the application or analytic layer and do the process there, but retrieve calculated results to be later used. This reduces significantly the resources needed for such operations, along with the observed latency, thus being as much closer as possible to offer near real time analytics. However, the analytical operations includes an inherit complexity, In order for any data management system to calculate the results, this implies the scanning (or access) of a plethora of data elements that reside in a big data set. Each invocation of such operation is time consuming and demands the consumption of significant resources, even if they are performed close to the storage itself. With our innovation, our component can calculate these results incrementally, that is, as data modification operations occur in parallel. This means that the end user can observe minimum latency, as the result is pre-calculated and modified incrementally. This can happen while database transactional semantics are ensured on the other side, thus, having the results being consistent in case of parallel modifications of the data. This allows for the provision of real-time analytics (as latency is minimized) while data can be concurrently ingested at the same time (as database transactions are enforced).
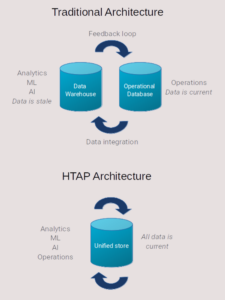
The second innovation of this component is its ability of performing advanced query processing in an energy efficient fashion. Firstly, by exploiting the incremental analytics part, it does not have to calculate every time the analytic result. This results in reduced energy consumption. Furthermore, based on the novel indexing mechanism and the implementation of the query engine, the module can offer reduced energy consumption by managing data in a more sophisticated manner. End-users can take advantage of this feature while designing their applications or AI data pipelines as their overall solution can result in reduced carbon footprint compared to the greedy consumption of resources that complex AI analytic often require.
Currently, within the FAME project, this innovation has been integrated with the Motor Oil pilot use case. This use case requires to periodically collect IoT data from sensors deployed within the infrastructure of the Motor Oil, and then to perform analytics for malfunction predictions. Using our novel functionality, this can be performed effectively in both time and energy consuming terms, leading to a significant reduction of the overall latency of such operations and the reduction of the overall carbon footprint required to perform the processing.
More info:
LeanXcale